bigdata - introduction
big data
Big Data is a portfolio of technologies that were designed to store, manage and analyze data that is too large to fit on a single machine while accommodat-ing for the issue of growing discrepancy between capacity, throughput and latency.
data independence
Data independence means that the logical view on the data is cleanly separated, decoupled, from its physical storage.
architecture
Stack: storage, compute, model ,language
data model
what data looks like and what you can do with it.
data shapes
tables, trees, cubes
table
Row(Tuple), Column(Attribute), Primary Key,Value.
relational tables
schema: A set of attributes.
extension: A set/bag/list of tuples.
Three constraints: Relational integrity, domain integrity and atomic integrity.
Superkey, Candidate key(minimal superkey).
Database Normalization
In database management systems (DBMS), normal forms are a series of guidelines that help to ensure that the design of a database is efficient, organized, and free from data anomalies.
First Normal Form (1NF):In 1NF, each table cell should contain only a single value, and each column should have a unique name.
Second Normal Form (2NF): 2NF eliminates redundant data by requiring that each non-key attribute be dependent on the primary key.
Third Normal Form (3NF): 3NF builds on 2NF by requiring that all non-key attributes are independent of each other.
Denormalization
Denormalization is a database optimization technique in which we add redundant data to one or more tables. This can help us avoid costly joins in a relational database. Note that denormalization does not mean ‘reversing normalization’ or ‘not to normalize’. It is an optimization technique that is applied after normalization.
SQL
SQL was originally named SEQUEL, for Structured English QUEry Language. SQL is a declarative language, which means that the user specifies what they want, and not how to compute it: it is up to the underlying system to figure out how to best execute the query.
View and Table
The view is a result of an SQL query and it is a virtual table, whereas a Table is formed up of rows and columns that store the information of any object and be used to retrieve that data whenever required. A view contains no data of its own but it is like a ‘window’ through which data from tables can be viewed or changed. The view is stored as a SELECT statement in the data dictionary. Creating a view fulfills the requirement without storing a separate copy of the data because a view does not store any data of its own and always takes the data from a base table. as the data is taken from the base table, accurate and up-to-date information is required.
SQL:1999 added the with clause to define “statement scoped views”. They are not stored in the database schema: instead, they are only valid in the query they belong to. This makes it possible to improve the structure of a statement without polluting the global namespace.With is not a stand alone command like create view is: it must be followed by select.
Natural Join and Inner Join
Natural Join joins two tables based on the same attribute name and datatypes. The resulting table will contain all the attributes of both the table but keep only one copy of each common column while Inner Join joins two tables on the basis of the column which is explicitly specified in the ON clause. The resulting table will contain all the attributes from both tables including the common column also.
data storage
Stack: Storage, Encoding, Syntax, Data models, Validation, Processing, Indexing, Data stores,Querying, User interfaces.
database and data lake
two main paradigms for storing and retrieving data:database and data lake. Data can be imported into the database (this is called ETL, for Extract-Transform-Load. ETL is often used as a verb).The data is internally stored as a proprietary format that is optimized to make queries faster. This includes in particular building indices on the data.
On the other hand, data can also just be stored on some file system.This paradigm is called the data lake paradigm and gained a lot of popularity in the past two decades. It is slower, however users can start querying their data without the effort of ETLing.
scaling up and scaling out
First, one can buy a bigger machine: more memory, more or faster CPU cores, a larger disk, etc. This is called scaling up. Second, one can buy more, similar machines and share the work across them. This is called scaling out.
Object stores
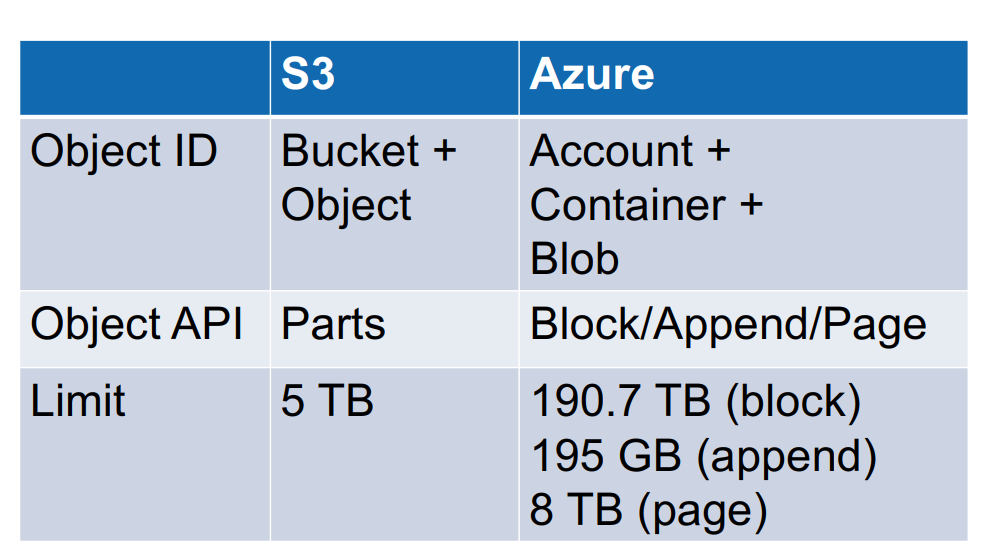
Amazon’s object storage system is called Simple Storage Service, abbreviated S3. From a logical perspective, S3 is extremely simple: objects are organized in buckets. Buckets are identified with a bucket ID, and each object within a bucket is identified with an Object ID.
CAP theorem
Consistency: at any point in time, the same request to any server returns the same result, in order words, all nodes see the same data;
Availability: the system is available for requests at all times with very high availability.
Partition tolerance: the system continues to function even if the network linking its machines is occasionally partitioned.
The CAP theorem is basically an impossibility triangle: a system cannot guarantee at the same time: usually are CP,AP or AC.
REST APIs
REST (Representational State Transfer) is an architectural style for designing networked applications.RESTful services often use HTTP as the communication protocol. A client and server communicated with the HTTP protocol interact in terms of methods applied to resources.A resource is referred to with what is called a URI. URI stands for Uniform Resource Identifier. A client can act on resources by invoking methods, with an optional body. The most important methods are: GET, PUT,DELETE,POST.
REST is not a standard or protocol, this is an approach to or architectural style for writing API.REST is an architectural style, and RESTful is the interpretation of it. That is, if your back-end server has REST API and you make client-side requests (from a website/application) to this API, then your client is RESTful. All requests you make have their HTTP status codes. There are a lot of them and they are divided into 5 classes. The first number indicates which of them a code belongs to:
1xx - informational
2xx - success
3xx - redirection
4xx - client error
5xx - server error
Amazon S3 and Azure Blob Storage
Key-value store
A key-value store differs from a typical relational database in three aspects: • Its API is considerably simpler than that of a relational database (which comes with query languages) • It does not ensure atomic consistency; instead, it guarantees eventual consistency, which we covered earlier in this Chapter. • A key-value store scales out well, in that it is very fast also at large scales.
Amazon Dynamo
It is itself based (with some modifications) on the Chord protocol, which is a Distributed Hash Table.On the physical level, a distributed hash table is made of nodes (the machines we have in a data center, piled up in racks) that work following a few design principles. The first design principle is incremental stability. This means that new nodes can join the system at any time, and nodes can leave the system at any time, sometimes gracefully, sometimes in a sudden crash.The second principle is symmetry: no node is particular in any way The third principle is decentralization: there is no “central node” that orchestrates the others.The fourth principle is heterogeneity: the nodes may have different CPU power, amounts of memory, etc.
A central aspect of the design of a distributed hash table, and part in particular of the Chord protocol, is that every logical key is hashed to bits that we will call IDs. In the case of Dynamo, the hash is made of 128 bits (7 bytes).In the chord protocol, a technology called a finger table is used. Each node knows the next node clockwise, and the second node, and the 4th node, and the 8th node. Dynamo changes this design to so-called “preference lists”: each node knows, for every key (or key range), which node(s) are responsible (and hold a copy) of it. This is done by associating every key (key range) with a list of nodes, by decreasing priority (going down the ring clockwise).
Distributed hash tables, including Dynamo, are typically AP. A fundamental conceptual tool in AP systems is the use of vector clocks.Vector clocks are a way to annotate the versions when they follow a DAG structure.A vector clock can logically be seen as a map from nodes (machines) to integers, i.e., the version number is incremented per machine rather than globally.
vector clock
Lamport’s logical clock
Lamport’s Logical Clock was created by Leslie Lamport. It is a procedure to determine the order of events occurring. It provides a basis for the more advanced Vector Clock Algorithm. Due to the absence of a Global Clock in a Distributed Operating System Lamport Logical Clock is needed.
Implementation Rules:
[IR1]: If a -> b [‘a’ happened before ‘b’ within the same process] then, Ci(b) =Ci(a) + d
[IR2]: Cj = max(Cj, tm + d) [If there’s more number of processes, then tm = value of Ci(a), Cj = max value between Cj and tm + d]
Vector Clocks in Distributed Systems
Vector Clock is an algorithm that generates partial ordering of events and detects causality violations in a distributed system.
How does the vector clock algorithm work :
Initially, all the clocks are set to zero.
Every time, an Internal event occurs in a process, the value of the processes’s logical clock in the vector is incremented by 1.
Every time, a process receives a message, the value of the processes’s logical clock in the vector is incremented by 1, and moreover, each element is updated by taking the maximum of the value in its own vector clock and the value in the vector in the received message (for every element).
To sum up, Vector clocks algorithms are used in distributed systems to provide a causally consistent ordering of events but the entire Vector is sent to each process for every message sent, in order to keep the vector clocks in sync.
partial order relation
Note that vector clocks can be compared to each other with a partial order relation ≤. A partial order relation is any relation that is reflexive, antisymmetric, and transitive. A total order relation is a partial order in which every element of the set is comparable with every other element of the set. All total order relations are partial order relations, but the converse is not always true.
references
https://www.geeksforgeeks.org/normal-forms-in-dbms/
https://www.geeksforgeeks.org/denormalization-in-databases/
https://www.geeksforgeeks.org/difference-between-view-and-table/
https://modern-sql.com/feature/with
https://www.geeksforgeeks.org/sql-natural-join/
https://mlsdev.com/blog/81-a-beginner-s-tutorial-for-understanding-restful-api
https://ghislainfourny.github.io/big-data-textbook/
https://www.geeksforgeeks.org/lamports-logical-clock/
bigdata - introduction
install_url to use ShareThis. Please set it in _config.yml.