bigdata - Map Reduce
Patterns of large-scale query processing
Textual input
We saw that the data we want to query can take many forms. First, it can be billions of lines of text. It can also be plenty of CSV lines. Some other formats (e.g., Parquet, …) can be binary. We also encountered HFiles in Chapter 6, which are lists of keyvalue pairs. In fact, Hadoop has another such kind of key-value-based format called Sequence File, which is simply a list of key-values, but not necessarily sorted by key (although ordered) and with keys not necessarily unique.
There are several practical motivations for the many-files pattern even in HDFS.
Querying pattern
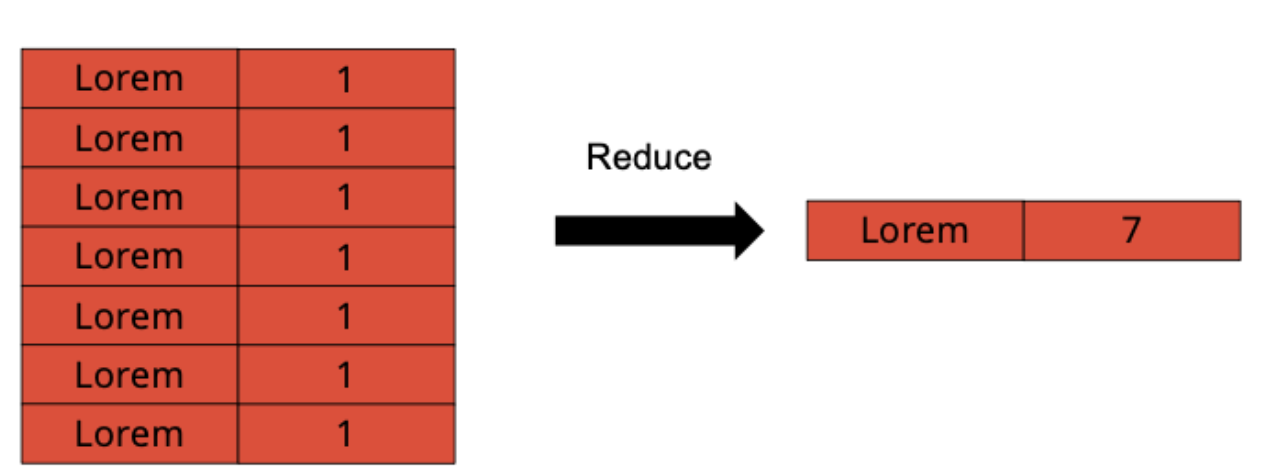
This is the motivation behind the standard MapReduce pattern: a map-like phase on the entire input, then a shuffle phase on the intermediate data, then another map-like phase (called reduce) producing the entire output
MapReduce Model
In MapReduce, the input data, intermediate data, and output data are all made of a large collection of key-value pairs (with the keys not necessarily unique, and not necessarily sorted by key). The types of the keys and values are known at compile-time (statically), and they do not need to be the same across all three collections.
MapReduce architecture
On a cluster, the architecture is centralized, just like for HDFS and HBase. In the original version of MapReduce, the main node is called JobTracker, and the worker nodes are called TaskTrackers.
In fact, the JobTracker typically runs on the same machine as the NameNode (and HMaster) and the TaskTrackers on the same machines as the DataNodes (and RegionServers). This is called “bring the query to the data.”
As the map phase progresses, there is a risk that the memory becomes full. But we have seen this before with HBase: the intermediate pairs on that machine are then sorted by key and flushed to the disk to a Sequence File. And as more flushes happen, these Sequence Files can be compacted to less of them, very similarly to HBase’s Log-Structured Merge Trees. When the map phase is over, each TaskTracker runs an HTTP server listening for connections, so that they can connect to each other and ship the intermediate data over to create the intermediate partitions ensuring that the same keys are on the same machines.This is the phase called shuffling. Then, the reduce phase can start. When the reduce phase is completed, each output partition will be output to a shard (as we saw, a file named incrementally) in the output destination (HDFS, S3, etc) and in the desired format.
Note that shuffling can start before the map phase is over, but the reduce phase can only start after the map phase is over.
MapReduce input and output formats
Impedance mismatch
MapReduce can read its input from files lying in a data lake as well as directly from a database system such as HBase or a relational database management system. MapReduce only reads and writes lists of key-value pairs, where keys may be duplicates and need not appear in order. However, the inputs we considered are not key-value pairs. So we need an additional mechanism that allows MapReduce to interpret this input as key-value pairs. For tables, whereas relational or in a wide column stores, this is relatively easy: indeed, tables have primary keys, consisting of either a single column or multiple columns. Thus, each tuple can be interpreted as a key-value pair.
Mapping files to pairs
How do we read a (possibly huge) text file as a list of key-value pairs? The most natural way to do so is to turn each line of text in a key value pair1: the value is the string corresponding to the entire line, while the key is an integer that expresses the position (as a number of characters), or offset, at which the line starts in the current file being read.
A few examples
Counting words
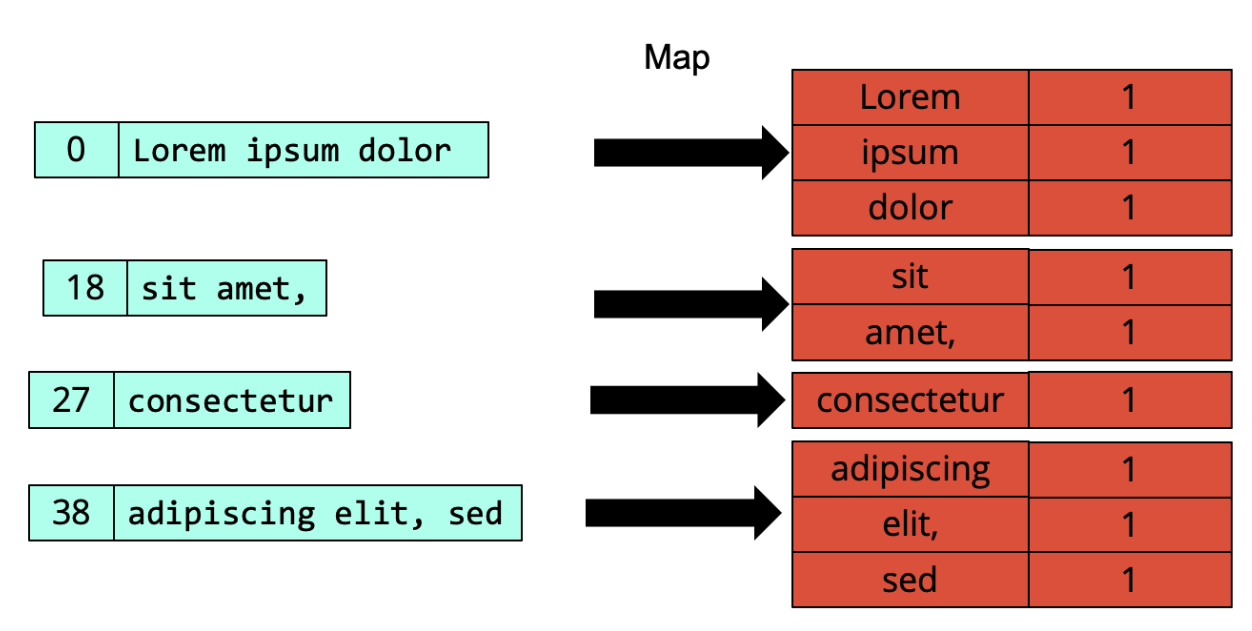
Selecting
This is something easily done by having a map function that outputs a subset of its input, based on some predicate provided by the user.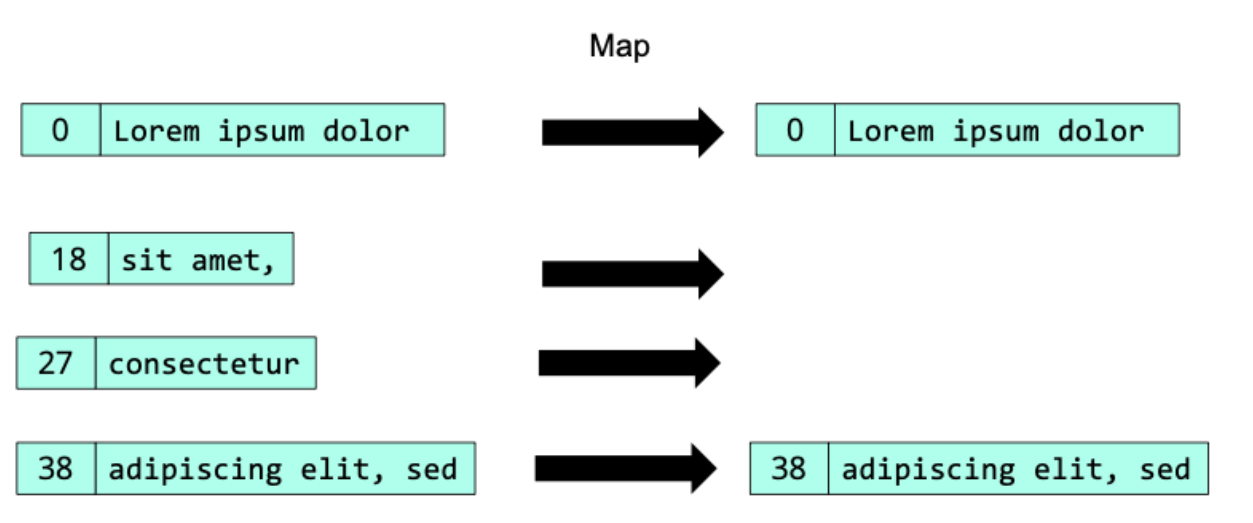
Here we notice that the output of the map phase already gives us the desired result; we still need to provide a reduce function, which is taken trivially as the identity function. This is not unusual (and there are also examples where the map function is trivial, and the reduce function is doing the actual processing).
Projecting
The map function can project this object to an object with less attributes: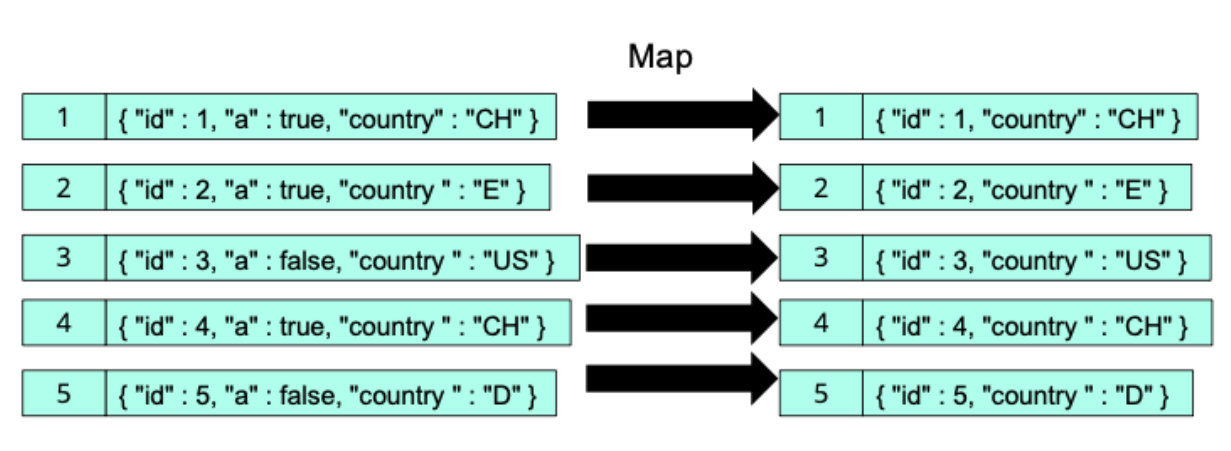
MapReduce and the relational algebra
As an exercise, try to figure out how to implement a GROUP BY clause and an ORDER BY clause. What about the HAVING clause? Naturally, executing these queries directly in MapReduce is very cumbersome because of the low-level code we need to write.
Combine functions and optimization
In addition to the map function and the reduce function, the user can supply a combine function. This combine function can then be called by the system during the map phase as many times as it sees fit to “compress” the intermediate key-value pairs. Strategically, the combine function is likely to be called at every flush of key-value pairs to a Sequence File on disk, and at every compaction of several Sequence Files into one.
However, there is no guarantee that the combine function will be called at all, and there is also no guarantee on how many times it will be called. Thus, if the user provides a combine function, it is important that they think carefully about a combine function that does not affect the correctness of the output data.
In fact, in most of the cases, the combine function will be identical to the reduce function, which is generally possible if the intermediate key-value pairs have the same type as the output key-value pairs, and the reduce function is both associative and commutative.
MapReduce programming API
Mapper classes
In Java, the user needs to define a so-called Mapper class that contains the map function, and a Reducer class that contains the reduce function. A map function takes in particular a key and a value. Note that it outputs key-value pairs via the call of the write method on the context, rather than with a return statement.
Reducer classes
A reduce function takes in particular a key and a list of values. Note that it outputs key-value pairs via the call of the write method on the context, rather than with a return statement.
Running the job
Finally, a MapReduce job can be created and invoked by supplying a Mapper and Reducer instance to the job. A combine function can also be supplied with the setCombinerClass method. It is also possible to use Python rather than Java, via the socalled Streaming API. The Streaming API is the general way to invoke MapReduce jobs in other languages than Java.
Using correct terminology
Functions
A map function is a mathematical, or programmed, function that takes one input key-value pair and returns zero, one or more intermediate key-value pairs.
A reduce function is a mathematical, or programmed, function that takes one or more intermediate key-value pairs and returns zero, one or more output key-value pairs.
A combine function is a mathematical, or programmed, function that takes one or more intermediate key-value pairs and returns zero, one or more intermediate key-value pairs.
Note that the combine function is an optional local aggregation step that occurs before shuffling and sorting, and its purpose is to reduce the amount of data that needs to be transferred to the reducers. The reduce function, on the other hand, performs the final aggregation and processing based on keys.
Tasks
A map task is an assignment (or “homework”, or “TODO”) that consists in a (sequential) series of calls of the map function on a subset of the input.
A reduce task is an assignment that consists in a (sequential) series of calls of the reduce function on a subset of the intermediate input.
We insist that the calls within a task are sequential, meaning that there is no parallelism at all within a task.
There is no such thing as a combine task. Calls of the combine function are not planned as a task, but is called ad-hoc during flushing and compaction.
Slots
The map tasks are processed thanks to compute and memory resources (CPU and RAM). These resources are called map slots. One map slot corresponds to one CPU core and some allocated memory. The number of map slots is limited by the number of available cores. Each map slot then processes one map task at a time, sequentially. The resources used to process reduce tasks are called reduce slots. So, there is no parallelism either within one map slot, or one reduce slot. In fact, parallelism happens across several slots.
Phases
The map phase thus consists of several map slots processing map tasks in parallel.
blocks vs. splits
HDFS blocks have a size of (at most) 128 MB. In every file, all blocks but the last one have a size of exactly 128 MB. Splits, however, only contain full records: a key-value pair will only belong to one split (and thus be processed by one map task).
bigdata - Map Reduce
install_url to use ShareThis. Please set it in _config.yml.