bigdata - YARN
Resource management
The first version of MapReduce is inefficient in several respects. For this reason, the architecture was fundamentally changed by adding a resource management layer to the stack, adding one more level of decoupling between scheduling and monitoring. A resource management system, here YARN, is a very important building block not only for a better MapReduce, but also for many other technologies running on a cluster.
Limitations of MapReduce in its first version
The JobTracker has a lot on its shoulders! It has to deal with resource management, scheduling, monitoring, the job lifecycle, and fault tolerance.The first consequence of this is scalability. The second consequence is the bottleneck that this introduces at the JobTracker level, which slows down the entire system. The third issue is that it is difficult to design a system that do many things well. The fourth issue is that resources are statically allocated to the Map or the Reduce phase, meaning that parts of the cluster remain idle during both phases. The fifth issue is the lack of fungibility between the Map phase and the Reduce phase.
YARN
General architecture
YARN means Yet Another Resource manager. It was introduced as an additional layer that specifically handles the management of CPU and memory resources in the cluster.
YARN, unsurprisingly, is based on a centralized architecture in which the coordinator node is called the ResourceManager, and the worker nodes are called NodeManagers. NodeManagers furthermore provide slots (equipped with exclusively allocated CPU and memory) known as containers.
When a new application is launched, the ResourceManager assigns one of the container to act as the ApplicationMaster which will take care of running the application. The ApplicationMaster can then communicate with the ResourceManager in order to book and use more containers in order to run jobs. This is a fundamental change from the initial MapReduce architecture, in which the JobTracker was also taking care of running the MapReduce job.
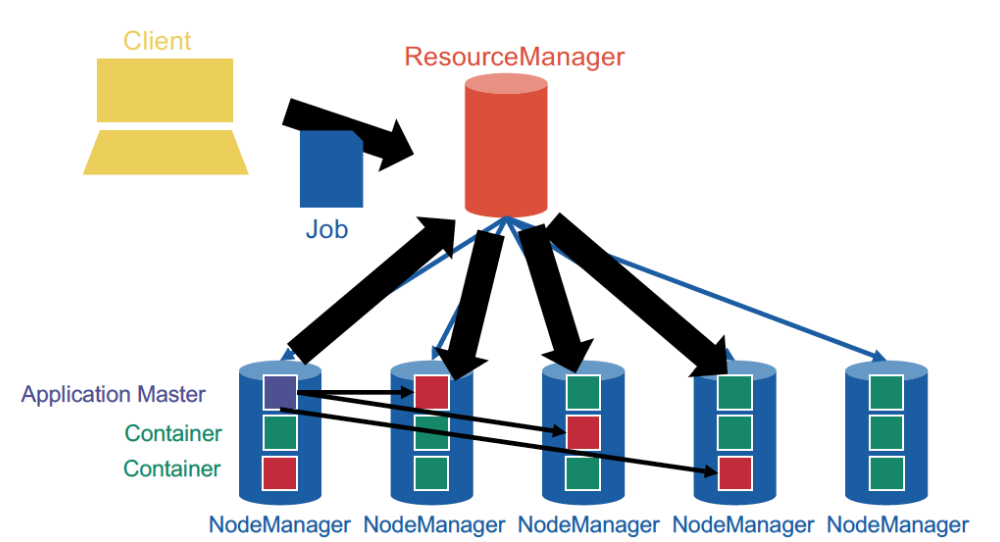
Thus, YARN cleanly separates between the general management of resources and bootstrapping new applications, which remains centralized on the coordinator node, and monitoring the job lifecycle, which is now delegated to one or more ApplicationMasters running concurrently. This means, in particular, that several applications can run concurrently in the same cluster. This ability, known as multi-tenancy, is very important for large companies or universities in order to optimize the use of their resources.
Resource management
In resource management, one abstracts away from hardware by distinguish between four specific resources used in a distributed database system. These four resources are: • Memory • CPU • Disk I/O • Network I/O.
ApplicationMasters can request and release containers at any time, dynamically. A container request is typically made by the ApplicationMasters with a specific demand. If the request is granted by the ResourceManager fully or partially, this is done indirectly by signing and issuing a container token to the ApplicationMaster that acts as proof that the resource was granted. The ApplicationMaster can then connect to the allocated NodeManager and send the token. The NodeManager will then check the validity of the token and provide the memory and CPU granted by the ResourceManager. The ApplicationMaster ships the code (e.g., as a jar file) as well as parameters, which then runs as a process with exclusive use of this memory and CPU.
Job lifecycle management and fault tolerance
Version 2 of MapReduce works on top of YARN by leaving the job lifecycle management to an ApplicationMaster. The ApplicationMaster requests containers for the Map phase, and sets these containers up to execute Map tasks. As soon as a container is done executing a Map task, the ApplicationMaster will assign a new Map task to this container from the remaining queue, until no Map tasks are left.
a container in the Map phase can contain several Map slots. Sharing memory and containers across slots in this way improves the overall efficiency, because setting up a container adds latency. It is thus more efficient to allocate 10 containers of each 4 cores, compared to 40 containers of each 1 core.
In the event of a container crashing during the Map phase, the ApplicationMaster will handle this by re-requesting containers and restarting the failed tasks. In the case that some data is lost in the Reduce phase, it is possible that the entire job must be restarted, because this the only way to recreate the intermediate data is to re-execute the Map tasks.
Scheduling
The ResourceManager keeps track of the list of available NodeManagers (who can dynamically come and go) and their status. Just like in HDFS, NodeManagers send periodic heartbeats to the ResourceManager to give a sign of life. The ResourceManager also offers an interface so that ApplicationMasters can register and send container requests. ApplicationMasters also send periodic heartbeats to the ResourceManager. It is important to understand that, unlike the JobTracker, the ResourceManager does not monitor tasks, and will not restart slots upon failure. This job is left to the ApplicationMasters.
Scheduling strategies
FIFO scheduling
In FIFO scheduling, there is one application at a time running on the entire cluster. When it is done, the next application runs again on the entire cluster, and so on.
Capacity scheduling
In capacity scheduling, the resources of the cluster are partitioned into several sub-clusters of various sizes. Each one of these sub-clusters has its own queue of applications running in a FIFO fashion within this queue. Capacity scheduling also exists in a more “dynamic flavour” in which, when a sub-cluster is not currently used, its resources can be temporarily lent to the other sub-clusters. This is also in the spirit of usage maximization.
Fair scheduling
Fair scheduling involves more complex algorithms that attempt to allocate resources in a way fair to all users of the cluster and based on the share they are normally entitled to. fair scheduling consists on making dynamic decisions regarding which requests get granted and which requests have to wait. Fair scheduling combines several ways to compute cluster shares: Steady fair share: this is the share of the cluster officially allocated to each department. Instantaneous fair share: this is the fair share that a department should ideally be allocated (according to economic and game theory considerations) at any point in time. This is a dynamic number that changes constantly, based on departments being idle: if a department is idle, then the instantaneous fair share of others department becomes higher than their steady fair shares. Current share: this is the actual share of the cluster that a department effectively uses at any point in time. This is highly dynamic. The current share does not necessarily match the instantaneous fair share because there is some inertia in the process: a department might be using more resources while another is idle. When the other department later stops being idle, these resources are not immediately withdrawn from the first department; rather, the first department will stop getting more resources, and the second department will gradually recover these resources as they get released by the first department.
The easiest case of fair scheduling is when only one resource is considered: for example, only CPU cores, or only memory. Things become more complicated when several resources are considered, in practice both CPU cores and memory. This problem was solved game-theoretically with the Dominant Resource Fairness algorithm. The two (or more) dimensions are projected again to a single dimension by looking at the dominant resource for each user.
exercise
motivation
improve hadoop 1.x by adding a layer YARN to separate resource management from data processing.
architecture
NodeMananger is generalized taskTracker.
On ResourceManager, there is an ApplicationManager rsponsible for admiting new jobs and collecting finished jobs and logs.
A scheduler has a global view to assign an ApplicationMaster. The applicationMaster will compute how many resources needed and send a request to the scheduler.
fault tolerance is provided by applicationMaster+NodeManager+HDFS.
bigdata - YARN
install_url to use ShareThis. Please set it in _config.yml.