bigdata - spark
Generic Dataflow Management
MapReduce is very simple and generic, but many more complex uses involve not just one, but a sequence of several MapReduce jobs. Furthermore, the MapReduce API is low-level, and most users need higherlevel interfaces, either in the form of APIs or query languages. This is why, after MapReduce, another generation of distributed processing technologies were invented. The most popular one is the open source Apache Spark.
A more general dataflow model
MapReduce consists of a map phase, followed by shuffling, followed by a reduce phase. In fact, the map phase and the reduce phase are not so different: both involve the computation of tasks in parallel on slots.
Resilient distributed datasets
The first idea behind generic dataflow processing is to allow the dataflow to be arranged in any distributed acyclic graph (DAG).
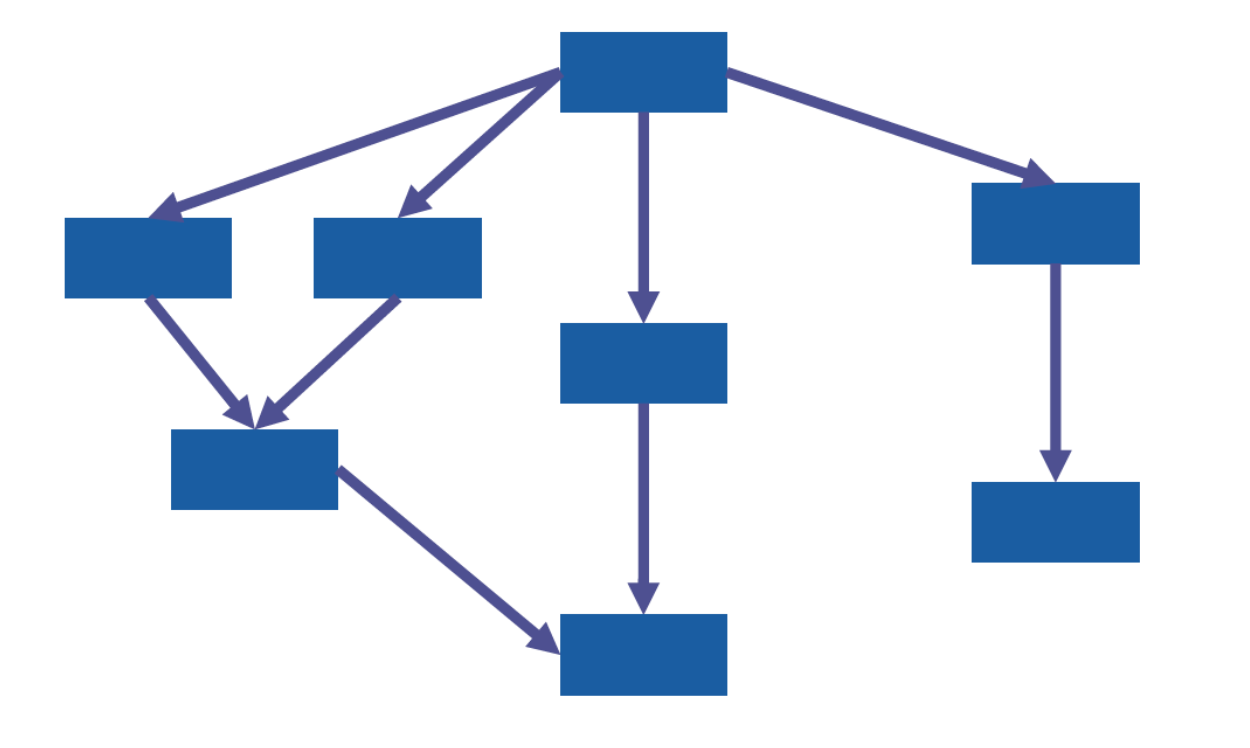
All the rectangular nodes in the above graph correspond to intermediate data. They are called resilient distributed datasets, or in short, RDDs.
A major difference with MapReduce, though, is that RDDs need not be collections of pairs. In fact, RDDs can be (ordered) collections of just about anything: strings, dates, integers, objects, arrays, arbitrary JSON values, XML nodes, etc.The only constraint is that the values within the same RDD share the same static type, which does not exclude the use of polymorphism.
The RDD lifecycle
Creation
RDDs undergo a lifecycle. First, they get created. RDDs can be created by reading a dataset from the local disk, or from cloud storage, or from a distributed file system, or from a database source, or directly on the fly from a list of values residing in the memory of the client using Apache Spark
Transformation
Then, RDDs can be transformed into other RDDs. Mapping or reducing, in this model, become two very specific cases of transformations. However, Spark allows for many, many more kinds of transformations. This also includes transformations with several RDDs as input.
Action
RDDs can also undergo a final action leading to making an output persistent. This can be by outputting the contents of an RDD to the local disk, to cloud storage, to a distributed file system, to a database system, or directly to the screen of the user.
Lazy evaluation
Another important aspect of the RDD lifecycle is that the evaluation is lazy: in fact, creations and transformations on their own do nothing. It is only with an action that the entire computation pipeline is put into motion, leading to the computation of all the necessary intermediate RDDs all the way down to the final output corresponding to the action.
Transformations
Unary transformations
Let us start with unary transformations, i.e., those that take a single RDD as their input.
Binary transformations
There are also transformations that take two RDDs as input.
Pair transformations
Spark has transformations specifically tailored for RDDs of key-value pairs.
Actions
Gathering output locally
The collect action downloads all values of an RDD on the client machine and outputs them as a (local) list. It is important to only call this action on an RDD that is known to be small enough (e.g., after filtering) to avoid a memory overflow.
The count action computes (in parallel) the total number of values in the input RDD. This one is safe even for RDDs with billions of values, as it returns a simple integer to the client.
Writing to sharded datasets
There is also an action called saveAsTextFile that can save the entire RDD to a sharded dataset on Cloud storage (S3, Azure blob storage) or a distributed file system (HDFS).
Binary outputs can be saved with saveAsObjectFile.
Actions on Pair RDDs
Physical architecture
Narrow-dependency transformations
In a narrow-dependency transformation, the computation of each output value involves a single input value. In a narrow-dependency transformation, the computation of each output value involves a single input value.
By default, if the transformation is applied to an RDD freshly created from reading a dataset from HDFS, each partition will correspond to an HDFS block. Thus, the computation of the narrow-dependency transformation mostly involves local reads by short-circuiting HDFS.
In fact, the way this works is quite similar to MapReduce: the sequential calls of the transformation function on each input value within a single partition is called a task. And just like MapReduce, the tasks are assigned to slots. These slots correspond to cores within YARN containers. YARN containers used by Spark are called executors. The processing of the tasks is sequential within each executor, and tasks are executed in parallel across executors. And like in MapReduce, a queue of unprocessed tasks is maintained, and everytime a slot is done, it gets a new task. When all tasks have been assigned, the slots who are done become idle and wait for all others to complete.
Chains of narrow-dependency transformations
In fact, on the physical level, the physical calls of the underlying map/filter/etc functions are directly chained on each input value to directly produce the corresponding final, output value, meaning that the intermediate RDDs are not even materialized anywhere and exist purely logically.
Such a chain of narrow-dependency transformations executed efficiently as a single set of tasks is called a stage, which would correspond to what is called a phase in MapReduce.
Physical parameters
Users can parameterize how many executors there are, how many cores there are per executor and how much memory per executor (remember that these then correspond to YARN container requests).
Shuffling
What about wide-dependency transformations? They involve a shuffling of the data over the network, so that the data necessary to compute each partition of the output RDD is physically at the same location.Thus, on the high-level of a job, the physical execution consists of a sequence of stages, with shuffling happening everytime a new stage begins.
Optimizations
Pinning RDDs
Everytime an action is triggered, all the computations of the ”reverse transitive closure” (i.e., all the way up the DAG through the reverted edges) are set into motion. In some cases, several actions might share subgraphs of the DAG. It makes sense, then, to “pin” the intermediate RDD by persisting it.
Pre-partitioning
Shuffle is needed to bring together the data that is needed to jointly contribute to individual output values. If, however, Spark knows that the data is already located where it should be, then shuffling is not needed.
DataFrames in Spark
Data independence
Unlike a relational database that has everything right off-theshelf, with RDDs, the user has to re-implement all the primitives they need. This is a breach of the data independence principle. The developers behind Spark addressed this issue in a subsequent version of Spark by extending the model with support for DataFrames and Spark SQL, bringing back a widely established and popular declarative, high-level language into the ecosystem.
A specific kind of RDD
A DataFrame can be seen as a specific kind of RDD: it is an RDD of rows (equivalently: tuples, records) that has relational integrity, domain integrity, but not necessarily atomic integrity.
Performance impact
DataFrames are stored column-wise in memory, meaning that the values that belong to the same column are stored together. Furthermore, since there is a known schema, the names of the attributes need not be repeated in every single row, as would be the case with raw RDDs. DataFrames are thus considerably more compact in memory than raw RDDs.
Generally, Spark converts Spark SQL to internal DataFrame transformation and eventually to a physical query plan. An optimizer known as Catalyst is then able to find many ways of making the execution faster.
Input formats
Note that Spark automatically infers the schema from discovering the JSON Lines file, which adds a static performance overhead that does not exist for raw RDDs.
DataFrame transformations
It is also possible, instead of Spark SQL, to use a transformation API similar to (but distinct from) the RDD transformation API.
Unlike the RDD transformation API, there is no guarantee that the execution will happen as written, as the optimizer is free to reorganize the actual computations.
DataFrame column types
DataFrames also support the three structured types: arrays, structs, and maps. As a reminder, structs have string keys and arbitrary value types and correspond to generic JSON objects, while in maps, all values have the same type. Thus, structs are more common than maps.
The Spark SQL dialect
Note that both GROUP BY and ORDER BY will trigger a shuffle in the system, even though this can be optimized as the grouping key and the sorting key are the same. The SORT BY clause can sort rows within each partition, but not across partitions, i.e., does not induce any shuffling. The DISTRIBUTE BY clause forces a repartition by putting all rows with the same value (for the specified field(s)) into the same new partition.
Note that the SORT BY clause is used to return the result rows sorted within each partition in the user specified order. When there is more than one partition SORT BY may return result that is partially ordered. This is different than ORDER BY clause which guarantees a total order of the output.
A word of warning must be given on SORT, DISTRIBUTE and CLUSTER clauses: they are, in fact, a breach of data independence, because they expose partitions.
Spark SQL also comes with language features to deal with nested arrays and objects. First, nested arrays can be navigated with the explode() function. Lateral views are more powerful and generic than just an explode() because they give more control, and they can also be used to go down several levels of nesting. A lateral view can be intuitively described this way: the array mentioned in the LATERAL VIEW clause is turned into a second, virtual table with the rest of the original table is joined. The other clauses can then refer to columns in both the original and second, virtual table.
exercise
RDD
Why RDD should be immutable and lazy: immutable is for lineage.
Why need RDD partitioning: parallel computing and reduce shuffling.
DataFrame API
For nested array,use array_contains.
spark SQL
In jupyter notebook, we can use “%load_ext sparksql_magic” directly.
reference
https://www.analyticsvidhya.com/blog/2016/10/spark-dataframe-and-operations/
bigdata - spark
install_url to use ShareThis. Please set it in _config.yml.