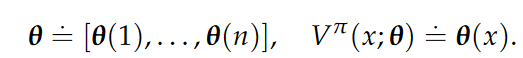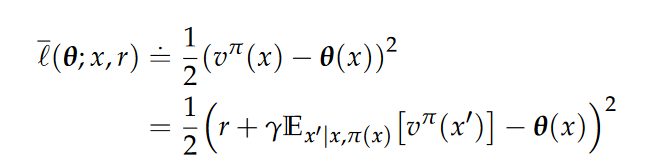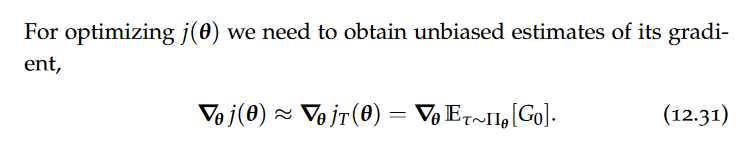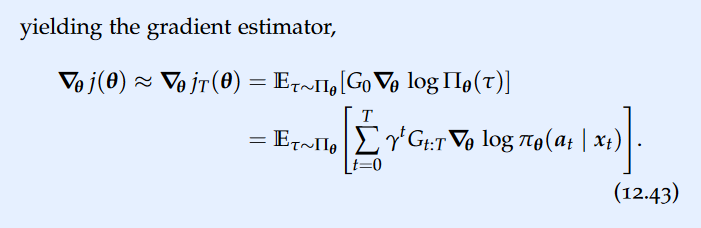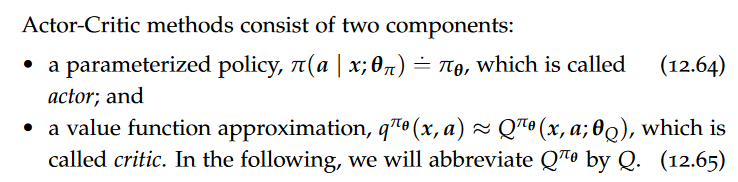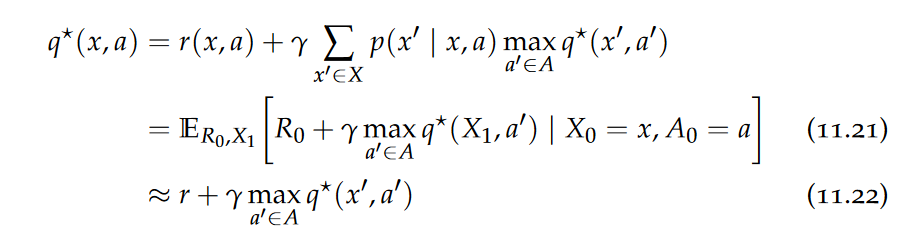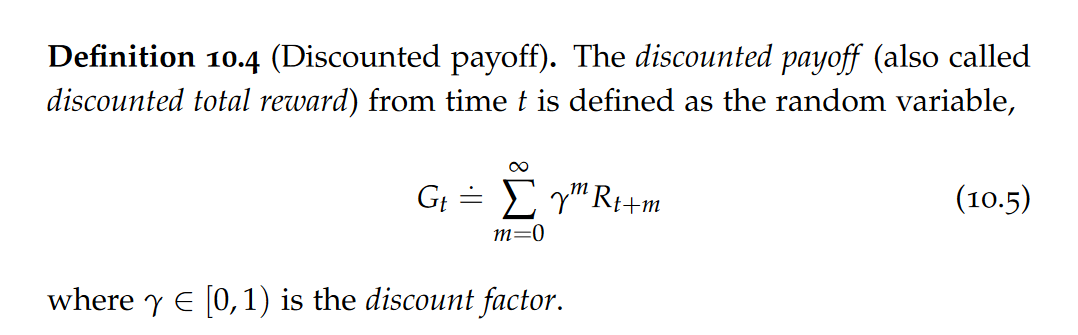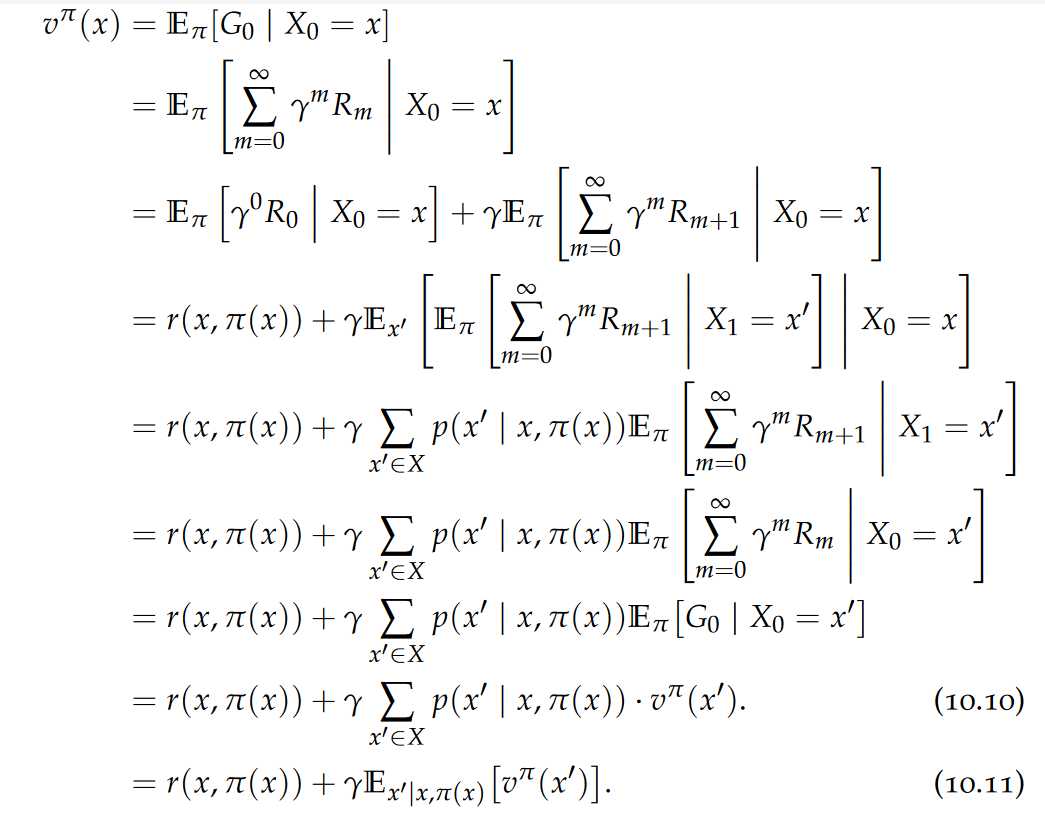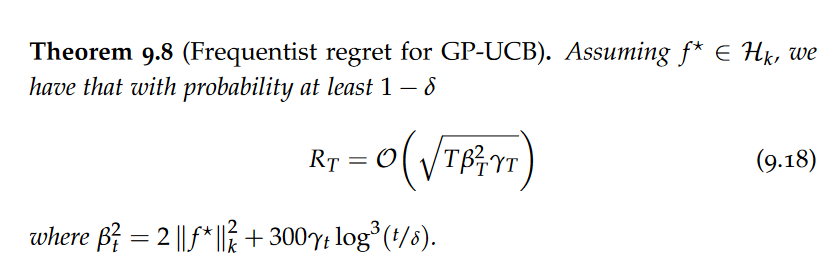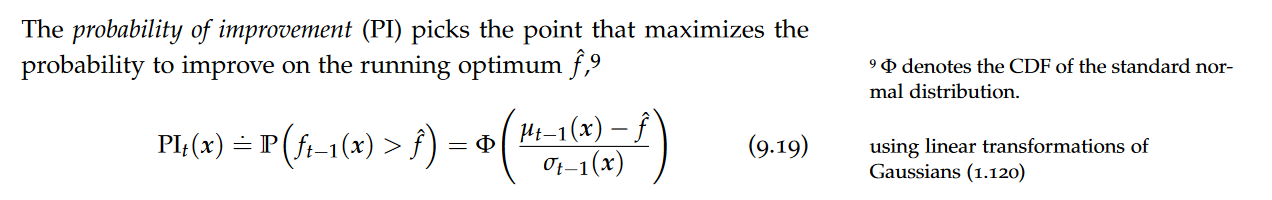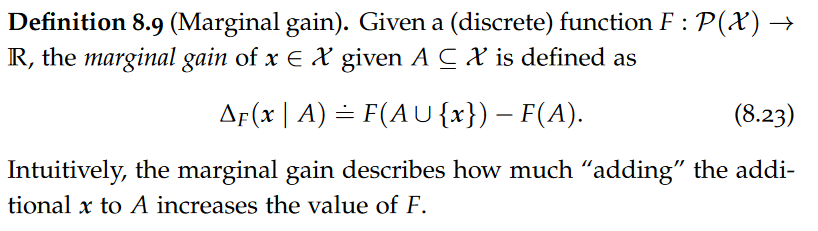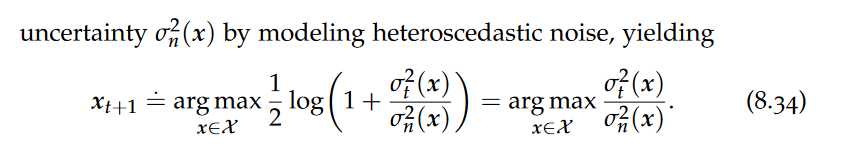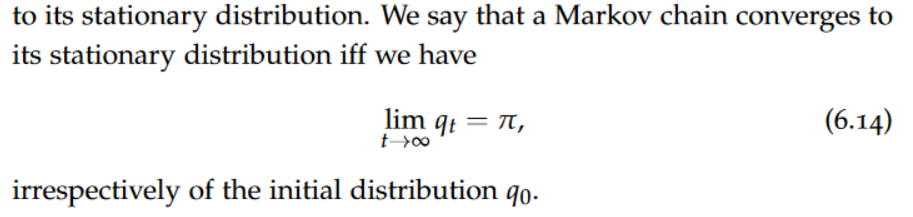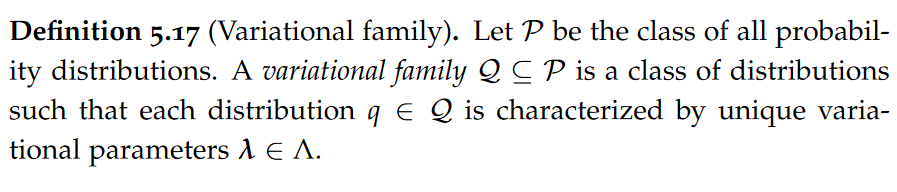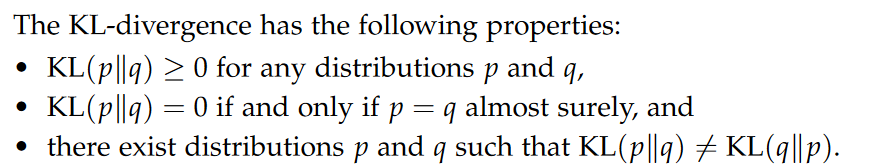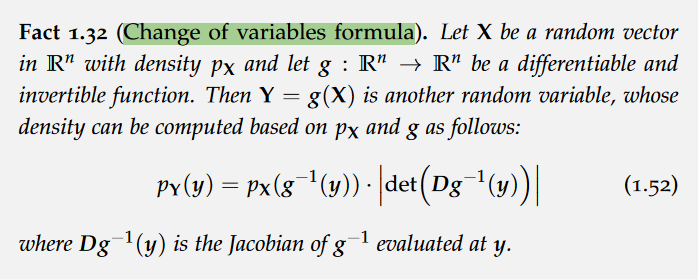fundamentals
probability
sample space, event space, σ-algebra and probability space
A probability space is a mathematical construct that consists of three elements: the sample space (S), the event space (E), and a probability measure (P). Additionally, a sigma-algebra (σ-algebra) is associated with the event space.
The sample space is the set of all possible outcomes of an experiment.The event space is a collection of subsets of the sample space.
A sigma-algebra is a collection of subsets of the sample space. It includes the sample space, is closed under complementation, and is closed under countable unions. The probability measure is a function that assigns probabilities to events.
probability mass function (PMF) and cumulative distribution function (CDF),probability density function (PDF)
The Probability Mass Function (PMF) is a function that gives the probability that a discrete random variable is exactly equal to a certain value. The Cumulative Distribution Function (CDF) of a random variable gives the probability that
X takes on a value less than or equal to x.
The Probability Density Function (PDF) is applicable to continuous random variables.The total area under the PDF curve is equal to 1.
Continuous Distributions
normal distribution(Gaussian):The Gaussian CDF cannot be expressed in closed-form. Note that the mean of a Gaussian distribution coincides with the maximizer of its PDF, also called mode of a distribution.
Joint Probability, Conditional Probability, Sum rule, Product rule(chain rule),the law of total probability
Joint probability refers to the probability of the occurrence of two or more events simultaneously. Conditional probability is the probability of one event occurring given that another event has already occurred. The sum rule, or addition rule, gives the probability of the union of two events. The product rule, also known as the chain rule, provides a way to express the joint probability of multiple events. The law of total probability is a way to express the probability of an event B by considering all possible ways in which
B can occur.
independence, conditional independence
Conditional independence does not necessarily imply unconditional independence, and vice versa.
Directed Graphical Models(Bayesian networks)
Directed graphical models (also called Bayesian networks) are often used to visually denote the (conditional) independence relationships of a large number of random variables.
Expectation, Covariance and Variance, Standard deviation,Law of total variance
Change of variables formula
Probabilistic inference
Bayes’ rule,Conjugate Priors
gaussian,Guassian random vector
Any affine transformation of a Gaussian random vector is a Gaussian random vector.
Supervised Learning and Point Estimates
Maximum Likelihood Estimation,Maximum a Posteriori Estimation,
The MLE and MAP estimate can be seen as a naïve approximation of probabilistic inference, represented by a point density which “collapses” all probability mass at the mode of the posterior distribution.
exercise
affine transformation,Jacobian matrix,
PML
linear regression
linear regression(MLE), ridge regression(MAP)
ridge,lasso
least absolute shrinkage and selection operator (lasso): Laplace prior, L1 regularization.
Ridge: Gaussian prior, L2 regularization.
The primary difference lies in the penalty terms: L1 regularization uses the sum of absolute values, and L2 regularization uses the sum of squared values.
L1 regularization tends to result in exact zeros, leading to sparse solutions, whereas L2 regularization generally leads to smaller, non-zero coefficients.
Bayesian linear regression (BLR)
Aleatoric and Epistemic Uncertainty
epistemic uncertainty: corresponds to the uncertainty about our model due to the lack of data. aleatoric uncertainty: “irreducible noise”, cannot be explained by the inputs and any model from the model class.
equation under the law of total variance.
kernel
Filtering
The process of keeping track of the state using noisy observations is also known as Bayesian filtering or recursive Bayesian estimation.
Kalman filter
A Kalman filter is simply a Bayes filter using a Gaussian distribution over the states and conditional linear Gaussians to describe the evolution of states and observations.
Gaussian Process
A Gaussian process is an infinite set of random variables such that any finite number of them are jointly Gaussian.
kernel function, feature space, RKHS,Stationarity and isotropy
A Gaussian process with a linear kernel is equivalent to Bayesian linear regression.
For ν = 1/2, the Matérn kernel is equivalent to the Laplace kernel. For ν → ∞, the Matérn kernel is equivalent to the Gaussian kernel.
Note that stationarity is a necessary condition for isotropy. In other words, isotropy implies stationarity.
skip 4.3.4
model selection
Maximizing the Marginal Likelihood
Marginal likelihood maximization is an empirical Bayes method. Often it is simply referred to as empirical Bayes.
this approach typically avoids overfitting even though we do not use a separate training and validation set. maximizing the marginal likelihood naturally encourages trading between a large likelihood and a large prior.
Approximations
random Fourier features,Bochner’s theorem,Uniform convergence of Fourier features
inducing points method,subset of regressors (SoR) approximation,fully independent training conditional (FITC) approximation
Variational Inference
Laplace Approximation,Bayesian Logistic Regression,
The Laplace approximation matches the shape of the true posterior around its mode but may not represent it accurately elsewhere — often leading to extremely overconfident predictions.
Variational family,mean-field distribution
Information Theory,Surprise,entropy,Jensen’s Inequality,Cross-entropy,KL-divergence,Forward and Reverse KL-divergence
The uniform distribution has the maximum entropy among all discrete distributions supported on {1, . . . , n}.
In words, KL(p∥q) measures the additional expected surprise when observing samples from p that is due to assuming the (wrong) distribution q.
It can be seen that the reverse KL-divergence tends to greedily select the mode and underestimating the variance which, in this case, leads to an overconfident prediction. The forward KL-divergence, in contrast, is more conservative.
Note, however, that reverse-KL is not greedy in the same sense as Laplace approximation, as it does still take the variance into account and does not purely match the mode of p.
Minimizing Forward-KL as Maximum Likelihood Estimation,Minimizing Forward-KL as Moment Matching
First, we observe that minimizing the forward KL-divergence is equivalent to maximum likelihood estimation on an infinitely large sample size.
A Gaussian qλ minimizing KL(p∥qλ) has the same first and second moment as p.
Evidence Lower Bound,Gaussian VI vs Laplace approximation, Gradient of Evidence Lower Bound(score gradients and Reparameterization trick)
maximizing the ELBO coincides with minimizing reverse-KL.
maximizing the ELBO selects a variational distribution q that is close to the prior distribution p(·) while also maximizing the average likelihood of the data p(y1:n | x1:n, θ) for θ ∼ q.
Note that for a noninformative prior p(·) ∝ 1, maximizing the ELBO is equivalent to maximum likelihood estimation.
skip 5.5.2
Markov Chain Monte Carlo Methods
The key idea of Markov chain Monte Carlo methods is to construct a Markov chain, which is efficient to simulate and has the stationary distribution p.
Markov Chains(Stationarity,convergence), Markov property,time-homogeneous Markov chains
Intuitively, the Markov property states that future behavior is independent of past states given the present state.
Stationary distribution,aperiodic,Ergodicity,Fundamental theorem of ergodic Markov chains
After entering a stationary distribution π, a Markov chain will always remain in the stationary distribution.
It can be shown that there exists a unique stationary distribution π if the Markov chain is irreducible, that is, if every state is reachable from every other state with a positive probability when the Markov chain is run for enough steps.
Even if a Markov chain has a unique stationary distribution, it must not converge to it.
In words, a Markov chain is aperiodic iff for every state x, the transition graph has a closed path from x to x with length k for all k ∈ N greater than some k0 ∈ N.
A Markov chain is ergodic iff there exists a t ∈ N0 such that for any x, x′ ∈ S we have p(t)(x′ | x) > 0.
A commonly used strategy to ensure that a Markov chain is ergodic is to add “self-loops” to every vertex in the transition graph.
An ergodic Markov chain has a unique stationary distribution π (with full support) irrespectively of the initial distribution q0. This naturally suggests constructing an ergodic Markov chain such that its stationary distribution coincides with the posterior distribution. If we then sample “sufficiently long”, Xt is drawn from a distribution that is “very close” to the posterior distribution.
How quickly does a Markov chain converge?(Total variation distance and Mixing time)
Detailed Balance Equation,Ergodic Theorem
A Markov chain that satisfies the detailed balance equation with respect to π is called reversible with respect to π.
Ergodic Theorem is a way to generalize the (strong) law of large numbers to Markov chains.
Elementary Sampling Methods,Metropolis-Hastings Algorithm,Metropolis-Hastings theorem, Gibbs Sampling
A popular example of a Metropolis-Hastings algorithm is Gibbs sampling.
Sampling as Optimization,Gibbs distribution,Langevin Dynamics,Metropolis adjusted Langevin algorithm (MALA) or Langevin Monte Carlo (LMC),unadjusted Langevin algorithm (ULA), Stochastic Gradient Langevin Dynamics, Hamiltonian Monte Carlo
A useful property is that Gibbs distributions always have full support. Observe that the posterior distribution can always be interpreted as a Gibbs distribution as long as prior and likelihood have full support.
Langevin dynamics adapts the Gaussian proposals of the Metropolis-Hastings algorithm to search the state space in an “informed” direction. The simple idea is to bias the sampling towards states with lower energy, thereby making it more likely that a proposal is accepted. A natural idea is to shift the proposal distribution perpendicularly to the gradient of the energy function. The resulting variant of Metropolis-Hastings is known as the Metropolis adjusted Langevin algorithm (MALA) or Langevin Monte Carlo (LMC).
The HMC algorithm is an instance of Metropolis-Hastings which uses momentum to propose distant points that conserve energy, with high acceptance probability.
path
target: show that the stationary distribution of a Markov chain coincides with the posterior distribution.
base: Detailed Balance Equation which shows that A Markov chain that satisfies the detailed balance equation with respect to π is called reversible with respect to π and if the Markov chain is reversible with respect to π then π is a stationary distribution. With posterior distribution p(x) = 1/Z q(x), substitute the posterior for π in the detailed balance equation, we can remove z, so we do not need to know the true posterior p to check that the stationary distribution of our Markov chain coincides with p, it suffices to know the finite measure q. However, until now, this does not allow us to estimate expectations over the posterior distribution. Note that although constructing such a Markov chain allows us to obtain samples from the posterior distribution, they are not independent. Thus, the law of large numbers and Hoeffding’s inequality do not apply, but there is a way to generalize the (strong) law of large numbers to Markov chains, which is Ergodic theorem.
Next we need to consider how to construct Markov chain with the goal of approximating samples from the posterior distribution p. One way is Metropolis-Hastings Algorithm, in which we are given a proposal distribution and we use the acceptance distribution to decide whether to follow the proposal. Another way is Gibbs sampling.
MCMC techniques can be generalized to
continuous random variables / vectors. Observe that the posterior distribution can always be interpreted as a Gibbs distribution as long as prior and likelihood have full support.
Langevin dynamics adapts the Gaussian proposals of the Metropolis-Hastings algorithm to search the state space in an “informed” direction. The simple idea is to bias the sampling towards states with lower energy, thereby making it more likely that a proposal is accepted. A natural idea is to shift the proposal distribution perpendicularly to the gradient of the energy function. The resulting variant of Metropolis-Hastings is known as the Metropolis adjusted Langevin algorithm (MALA) or Langevin Monte Carlo (LMC).
skip 6.3.5
BDL
Artificial Neural Networks,Activation Functions,
Non-linear activation functions allow the network to represent arbitrary functions. This is known as the universal approximation theorem.
Bayesian Neural Networks, Heteroscedastic Noise, Variational Inference,Markov Chain Monte Carlo, SWA,SWAG,Dropout and Dropconnect, Probabilistic Ensembles
Intuitively, variational inference in Bayesian neural networks can be interpreted as averaging the predictions of multiple neural networks drawn according to the variational posterior qλ.
Calibration,expected calibration error (ECE), maximum calibration error (MCE), Histogram binning, Isotonic regression, Platt scaling, Temperature scaling
We say that a model is wellcalibrated if its confidence coincides with its accuracy across many predictions. Compare within each bin, how often the model thought the inputs belonged to the class (confidence) with how often the inputs actually belonged to the class (frequency).
Sequential Decision-Making
Active Learning
Conditional Entropy,Joint entropy
A very intuitive property of entropy is its monotonicity: when conditioning on additional observations the entropy can never increase.
Mutual Information(information gain), the law of total expectation, data processing inequality, interaction information(Synergy and Redundancy), Submodularity of Mutual Information, Marginal gain, Submodularity, monotone,
data processing inequality: which says that processing cannot increase the information contained in a signal.
F is submodular iff “adding” x to the smaller set A yields more marginal gain than adding x to the larger set B.
I is monotone submodular.
Maximizing Mutual Information, Greedy submodular function maximization, Uncertainty Sampling, Marginal gain of maximizing mutual information,Bayesian active learning by disagreement (BALD)
skip proof of Theorem 8.15
Therefore, if f is modeled by a Gaussian and we assume homoscedastic noise, greedily maximizing mutual information corresponds to simply picking the point x with the largest variance. This algorithm is also called uncertainty sampling.
Experimental Design, Entropy Search
skip
Bayesian Optimization
Exploration-Exploitation Dilemma,Online Learning and Bandits, Multi-Armed Bandits, Regret, sublinear regret, Cesàro mean
Bayesian optimization can be interpreted as a variant of the MAB problem where there can be a potentially infinite number of actions (arms), but their rewards are correlated (because of the smoothness of the Gaussian process prior).
Acquisition Functions, Upper Confidence Bound, Bayesian confidence intervals, Regret of GP-UCB, Information gain of common kernels, Frequentist confidence intervals, probability of improvement, expected improvement (EI), Thompson Sampling, probability matching, Information-Directed Sampling
skip Information-Directed Sampling
Markov Decision Processes
Planning deals with the problem of deciding which action an agent should play in a (stochastic) environment. A key formalism for probabilistic planning in known environments are so-called Markov decision processes.
Policy,discounted payoff,state value function,state-action value function (also called Q-function)
A policy is a function that maps each state x ∈ X to a probability distribution over the actions.
Bellman Expectation Equation
Policy Evaluation, Fixed-point Iteration, contraction,Banach fixed-point theorem
Policy Optimization, Greedy Policies, Bellman Optimality Equation, Bellman’s theorem, Policy Iteration, Value Iteration,
In particular, if for every state there is a unique action that maximizes the state-action value function, the policy π⋆ is deterministic and unique.
Intuitively, the Bellman optimality equations express that the value of a state under an optimal policy must equal the expected return for the best action from that state.
Value iteration converges to an ε-optimal solution in a polynomial number of iterations. Unlike policy iteration, value iteration does not converge to an exact solution in general.
Partial Observability,
Whereas MDPs are controlled Markov chains, POMDPs are controlled hidden Markov models.
Tabular Reinforcement Learning
Trajectories, episodic setting, continuous setting, On-policy and Off-policy Methods,
on-policy methods are used when the agent has control over its own actions, in other words, the agent can freely choose to follow any policy. off-policy methods can be used even when the agent cannot freely choose its actions.
Model-based Approaches, Balancing Exploration and Exploitation, ε-greedy, Softmax Exploration(Boltzmann exploration), Rmax algorithm
skip Remark 11.3: Asymptotic convergence
Note that ε-greedy is GLIE with probability 1 if the sequence (εt)t∈N0 satisfies the RM-conditions (A.56), e.g., if εt = 1/t.
A significant benefit to model-based reinforcement learning is that it is inherently off-policy. That is, any trajectory regardless of the policy used to obtain it can be used to improve the model of the underlying Markov decision process. In the model-free setting, this not necessarily true.
Model-free Approaches, On-policy Value Estimation, bootstrapping, temporal-difference learning, SARSA, Off-policy Value Estimation, Q-learning, optimistic Q-learning
Model-free Reinforcement Learning
Value Function Approximation, DQN, experience replay, maximization bias, Double DQN
Policy Approximation(policy gradient methods), policy value function, Policy Gradient, Score gradient estimator, Score gradients with baselines, Downstream returns, REINFORCE algorithm
The main advantage of policy gradient methods such as REINFORCE is that they can be used in continuous action spaces. However, REINFORCE is not guaranteed to find an optimal policy. Even when operating in very small domains, REINFORCE can get stuck in local optima.
On-policy Actor-Critics,Advantage Function, Policy Gradient Theorem, Actor-Critic(Q actor-critic,Online actor-critic), advantage actor-critic, bias-variance tradeoff, trust-region policy optimization (TRPO), Proximal policy optimization (PPO)
One approach in the online setting (i.e., non-episodic setting), is to simply use SARSA for learning the critic. To learn the actor, we use stochastic gradient descent with gradients obtained using single samples.
Model-based Reinforcement Learning
Planning over Finite Horizons, receding horizon control (RHC), model predictive control (MPC), Random shooting methods
cheat sheet
from book
conditional distribution for gaussian;
Gaussian process posterior;
the predictive posterior at the test point;
common kernels;
the Hessian of the logistic loss;
Surprise,entropy,Jensen’s Inequality,Cross-entropy,KL-divergence,
ELBO,
the law of large numbers and Hoeffding’s inequality,
Hoeffding bound,
from exercise
Woodbury push-through identity;
Solution to problem 3.6;