什么是git
Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency.
使用Git
假设已经在电脑上安装好了Git,并配好了环境,在windows下,文件夹下右击出现了
Git Bash Here,就说明已经安装好了。
使用git需要首先建立一个仓库,之后就可以在这个仓库中对代码进行各种操作,过程中会使用到各种git命令,下面就介绍一下每个git命令的具体作用。
Git 基础命令
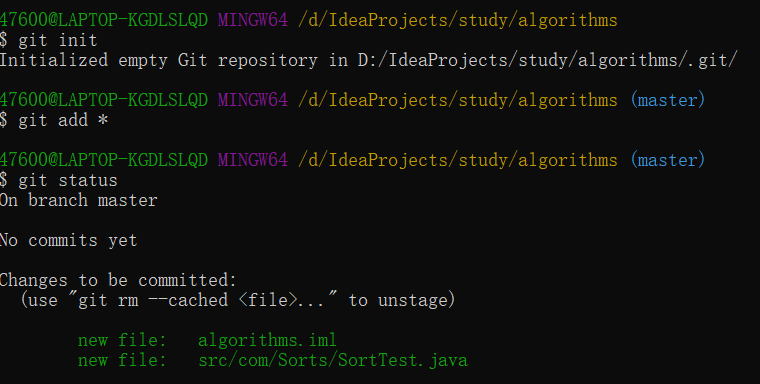
git init用于初始化一个仓库。在某个文件夹下打开Git Bash,运行完这个命令,文件夹下会生成一个.git文件夹,这个文件夹会记录以后的变更行为,但想要真正地追踪这些变更,还需要更多的操作,只有处于tracked状态下的文件,git才会追踪,后面会具体介绍。
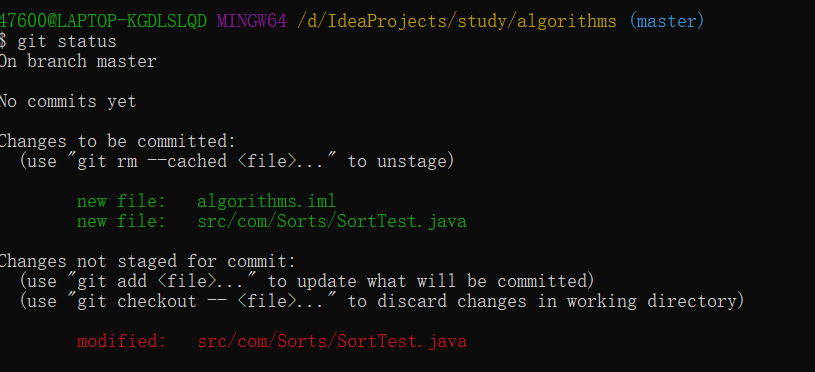
git status用于查看仓库中所有文件的状态。Git中文件有4种状态:untracked, unmodified ,
modified, staged,后三种状态属于tracked,这几个状态体现了git的原理。
新建一个文件的时候,这个文件处于untracked状态,对这个文件使用了 git add之后,这个文件进入staged状态,也就是暂存区,使用了git commit之后,这个文件进入unmodified状态,这才是实际提交了改动,如果编辑了这个文件,对这个文件进行了更改,便进入了modified状态。
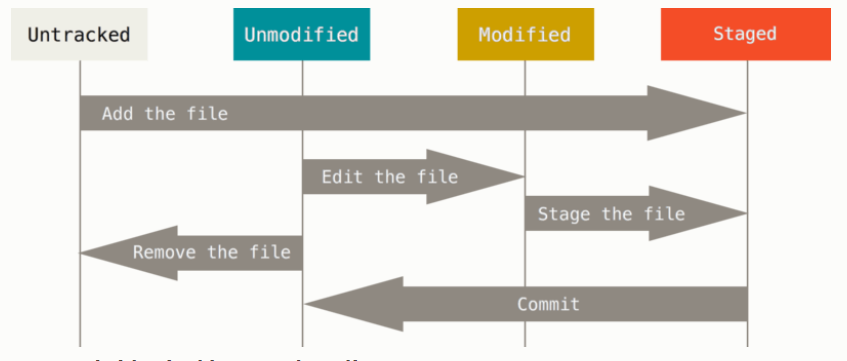
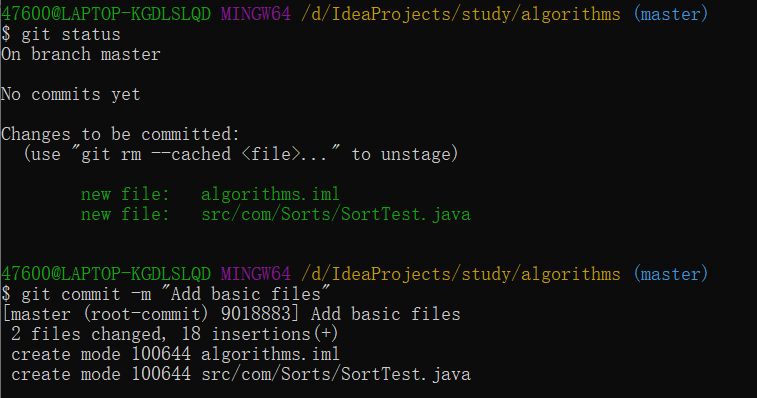
git add在上部分有介绍过,但是这个命令并不是添加文件到某个项目中的意思,准确地说这个命令是把想要提交的内容添加到准备提交的集合里,可以用这个命令来追踪新文件(add the file),暂存文件(stage the file),或者其它在commit之前的操作。如果在运行了git add之后又修改了文件,没有再次运行git add,就运行了commit,commit的是修改之前的内容。那么是不是每一次都要反复操作git add呢,其实还有别的方法可以跳过暂存区这一步,下面会说明。
git commit是提交变化到仓库里,提交到仓库里的几乎总是可以恢复的,后面会介绍如何恢复。git commit -a就可以跳过暂存区这一步,因为-a包含了所有改动过的文件。git commit -m可以加上这次提交的描述,
git rm用于删除文件,这里的删除有两种含义,从Git中删除和从工作目录中删除,如果只是想要Git不在追踪这个文件,需要使用git rm --cached。
git log用于回顾提交历史,运行这个命令可以看到提交的SHA-1 校验和,作者,提交时间和具体提交的内容。如果想要复原到某次提交时候的版本,这个命令是非常重要的,通过拿到每次提交的SHA-1 校验和,可以追踪到对应的版本。
git reset HEAD 用于取消暂存文件。
git checkout --用于撤销所作的修改。
Git 分支
分支就是与主线相对的,每个人都可以使用各自的分支进行工作,而不影响主线。在许多版本控制系统中,是需要创建一个完整的源项目副本来创建分支的,而Git不是这样的,Git处理分支的方式非常轻量,分支之间的操作非常迅速。
要理解Git是如何处理分支的,就要理解Git是如何实现对文件的追踪的。Git保存的是不同时刻的快照(Snapshot),进行提交操作时,Git会保存一个提交对象,这个对象包含了一个指向暂存内容快照的指针,还包含了作者、邮箱等内容以及指向它的父对象的指针,如果是第一次提交,是没有父对象的,而之后的提交,其父对象就是上一次提交。Git的分支,本质上就是指向提交对象的可变指针,所以不同的分支可以指向不同的内容,从而互不影响,而且Git的分支实质上就是一个包含所致对象校验和的文件,所以其创建和销毁都非常高效。
git branch就是创建分支的命令,这个命令会在当前的提交快照上创建一个指针。Git通过一个HEAD的特殊指针指向当前所在的本地分支,从而可以知道自己当前在哪一个分支上。
git branch -d用于删除分支。
git checkout是切换分支的命令。
git merge用于合并分支。当合并分支产生冲突时,Git会停下来,这时候需要手动解决这些冲突,解决完冲突之后,使用git add命令将冲突文件标记为冲突已解决。
远程仓库
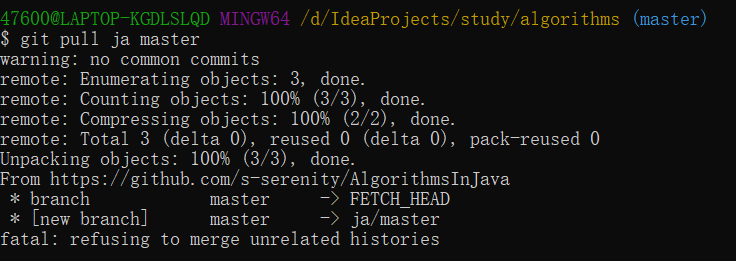
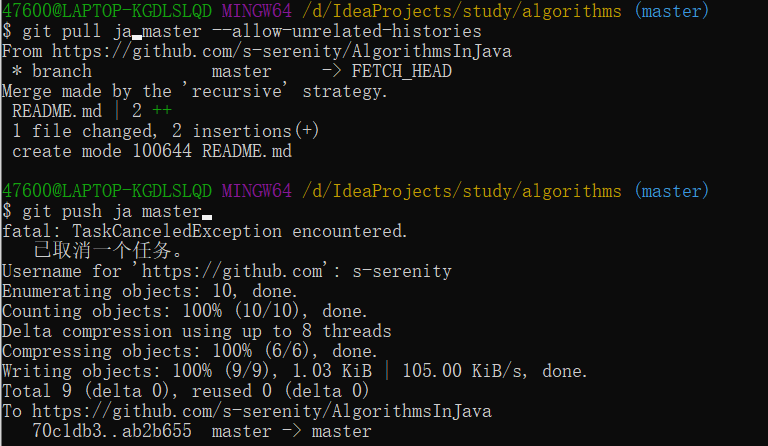
之前所述的内容,都是基于本地的操作,而如果想要在Git项目上进行协作,就需要一个公共的空间供项目参与者进行共同编辑,这就是远程仓库。远程仓库是指托管在因特网或其他网络中的你的项目的版本库,使用命令新建远程仓库的操作与本地是一致的,在github上create repository就可以新建一个远程仓库,本地和远程仓库之间通过SSH连接,完成SSH的公钥设置之后, 想要实现本地与远程仓库的内容交换,使用以下介绍的命令。
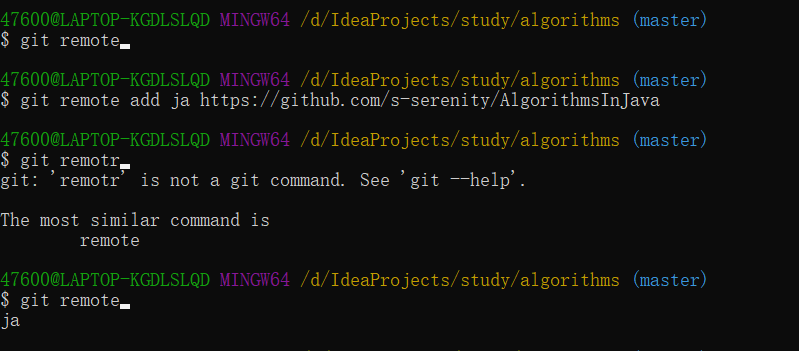
git remote add <shortname> <url>用于添加一个新的远程仓库。
git fetch用于从远程仓库中获取本地没有的数据,但是这个命令指挥把数据下载到本地仓库,并不会与本地仓库自动合并,想要实现自动合并,需要使用git pull命令。git clone可以把远程仓库的内容克隆到本地,并将远程仓库默认命名为”origin”。
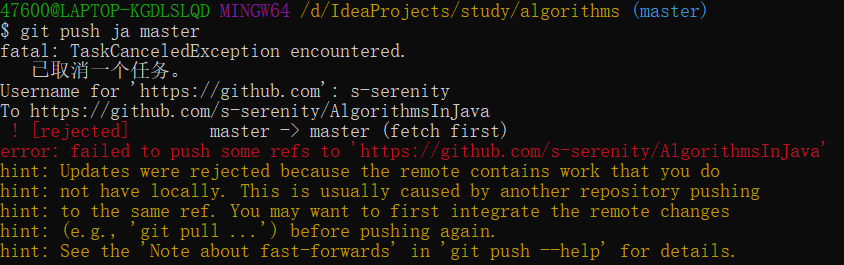
git push <remote> <branch>命令用于将本地内容推送到远程仓库上,只有具备远程仓库的写入权限,并且没有人推送过之前,这条命令才会生效,如果别人先推送了,需要先抓取别人的工作并合并到自己的工作中之后才能推送。
git remote show <remote>用于查看某一个远程仓库的具体新息。
git 别名
上述说了很多命令,有些命令也比较长,命令很多也比较难记下来,git提供了将这些命令起个别名的功能方便使用。
git config --global alias.co checkout就将checkout起了别名co,现在使用git co就相当于git checkout。