syntax
CSV
CSV is a textual format, in the sense that it can be opened in a text editor. CSV means comma-separated values. The main challenge with CSV files is that, in spite of a standard (RFC 4180), in practice there are many different dialects and variations, which limits interoperability. For example, another character can be used instead of the comma (tabulation, semi-colons, etc). Also, when a comma (or the special character used in its stead) needs to actually appear in a value, it needs to be escaped.
Data denormalization
Data denormalization makes a lot of sense in read-intensive scenarios in which not having to join brings a significant performance improvement.
The difference with CSV is that, in JSON, the attributes appear in every tuple, while in CSV they do not appear except in the header line. JSON is appropriate for data denormalization because including the attributes in every tuple allows us to drop the identical support requirement.
The generic name for denormalized data (in the same of heterogeneous and nested) is “semi-structured data”. Textual formats such as XML and JSON have the advantage that they can both be processed by computers, and can also be read, written and edited by humans. Another very important and characterizing aspect of XML and JSON is that they are standards: XML is a W3C standard. W3C, also known as the World Wide Web consortium, is the same body that also standardizes HTML, HTTP, etc. JSON is now an ECMA standard, which is the same body that also standardizes JavaScript.
Whichever syntax is used, they have in common the concept of well-formedness. A string is said to be well-formed if it belongs to the language. Concretely, when a document is well-formed XML, it means that it can be successfully opened by an editor as XML with no errors.
JSON
JSON stands for JavaScript Object Notation because the way it looks like originates from JavaScript syntax, however it is now living its own life completely independently of JavaScript.
JSON is made of exactly six building blocks: strings, numbers, Booleans, null, objects, and arrays. Strings are simply text. In JSON, strings always appear in double quotes. Obviously, strings could contain quotes and in order not to confuse them with the surrounding quotes, they need to be differentiated. This is called escaping and, in JSON, escaping is done with backslash characters ().
JSON generally supports numbers, without explicitly naming any types nor making any distinction between numbers apart from how they appear in syntax. The way a number appears in syntax is called a lexical representation, or a literal. JSON places a few restrictions: a leading + is not allowed. Also, a leading 0 is not allowed except if the integer part is exactly 0.
There are two Booleans, true and false. Arrays are simply lists of values. The concept of list is abstract and mathematical. The concept of array is the syntactic counterpart of a list. Objects are simply maps from strings to values. The concept of object is the syntactic counterpart of a map,i.e., an object is a physical representation of an abstract map that explicitly lists all string-value pairs. The keys of an object must be strings. The JSON standard recommends for keys to be unique within an object.
XML
XML stands for eXtensible Markup Language. It resembles HTML, except that it allows for any tags and that it is stricter in what it allows.
XML’s most important building blocks are elements, attributes, text and comments. XML is a markup language, which means that content is “tagged”. Tagging is done with XML elements. An XML element consists of an opening tag, and a closing tag. What is “tagged” is everything inbetween the opening tag and the closing tag. ags consist of a name surrounded with angle brackets < … >, and the closing tag has an additional slash in front of the name. We use a convenient shortcut to denote the empty element with a single tag and a slash at the end. For example, \
\
Unlike JSON keys, element names can repeat at will.
Attributes appear in any opening elements tag and are basically keyvalue pairs. Values can be either double-quoted or single-quoted. The key is never quoted, and it is not allowed to have unquoted values. Within the same opening tag, there cannot be duplicate keys. Attributes can also appear in an empty element tag. Attributes can never appear in a closing tag. It is not allowed to create attributes that start with XML or xml, or any case combination.
Text, in XML syntax, is simply freely appearing in elements and without any quotes (attribute values are not text!). Within an element, text can freely alternate with other elements. This is called mixed content and is unique to XML.
Comments in XML look like so: \. XML documents can be identified as such with an optional text declaration containing a version number and an encoding, like \<?xml version=”1.0” encoding=”UTF-8”?>. The version is either 1.0 or 1.1. Another tag that might appear is the doctype declaration, like \<!DOCTYPE person>.
Remember that in JSON, it is possible to escape sequences with a backslash character. In XML, this is done with an ampersand (&) character. There are exactly five possible escape sequences pre-defined in XML: . Escape sequences can be used anywhere in text, and in attribute values. At other places (element names, attribute names, inside comments), they will not be recognized.
. Escape sequences can be used anywhere in text, and in attribute values. At other places (element names, attribute names, inside comments), they will not be recognized.
There are a few places where they are mandatory:& and < MUST be escaped. ” and ‘ should also be escaped in quoted qttribute values.
Namespaces are an extension of XML that allows users to group their elements and attributes in packages, similar to Python modules, Java packages or C++ namespaces. A namespace is identified with a URI. A point of confusion is that XML namespaces often start with http://, but are not meant to be entered as an address into a browser. A namespace declaration is like: \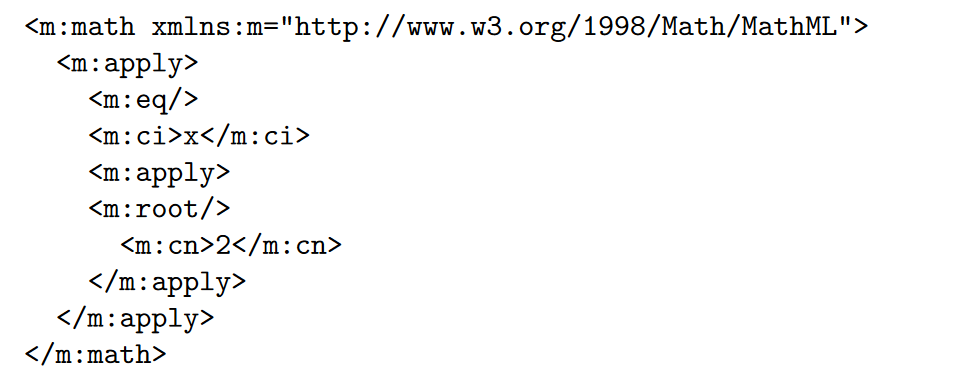
So, given any element, it is possible to find its local name, its (possibly absent) prefix, and its (possibly absent) namespace. The triplet (namespace, prefix, localname) is called a QName
Attributes can also live in namespaces, that is, attribute names are generally QNames. However, there are two very important aspects to consider. First, unprefixed attributes are not sensitive to default namespaces: unlike elements, the namespace of an unprefixed attribute is always absent even if there is a default namespace. Second, it is possible for two attributes to collide if they have the same local name, and different prefixes but associated with the same namespace (but again, we told you: do not do that!).